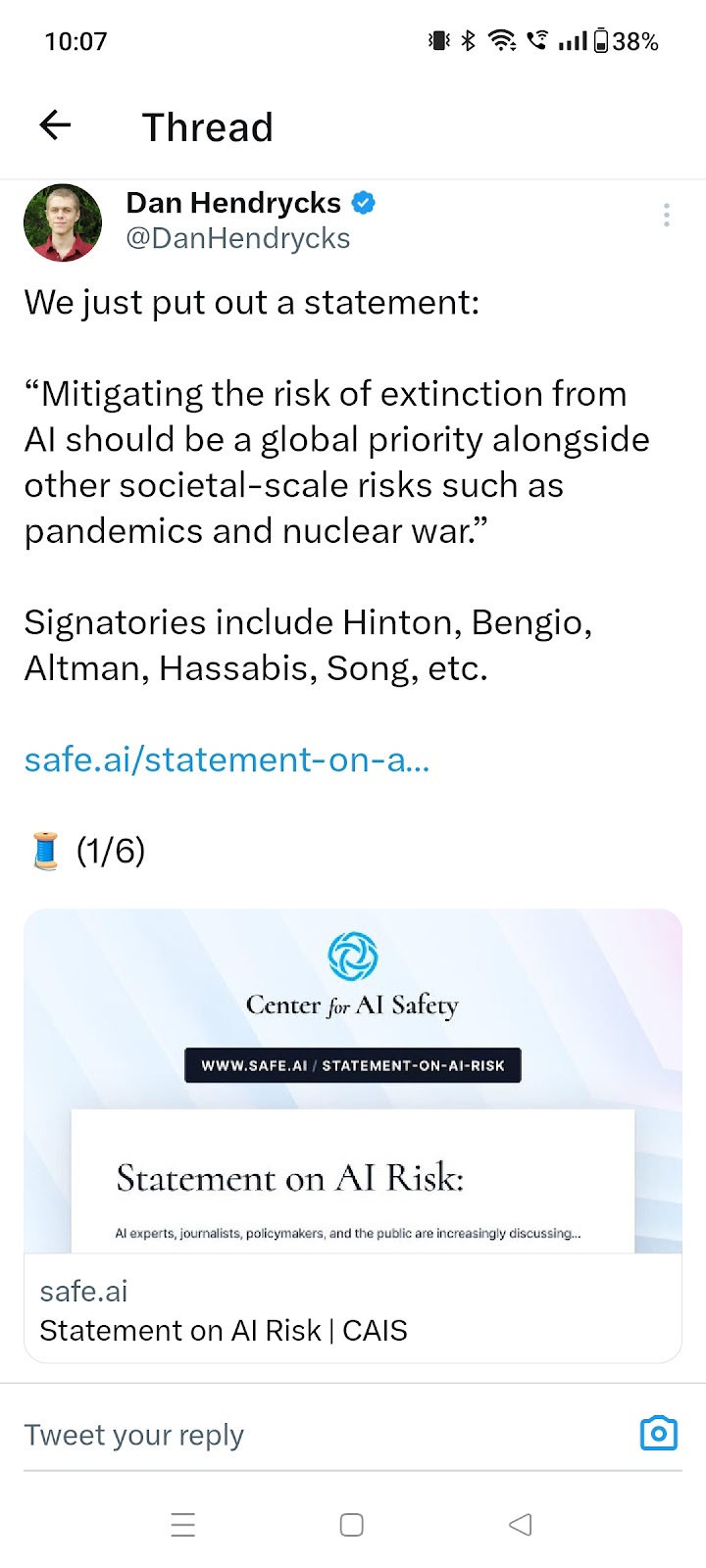
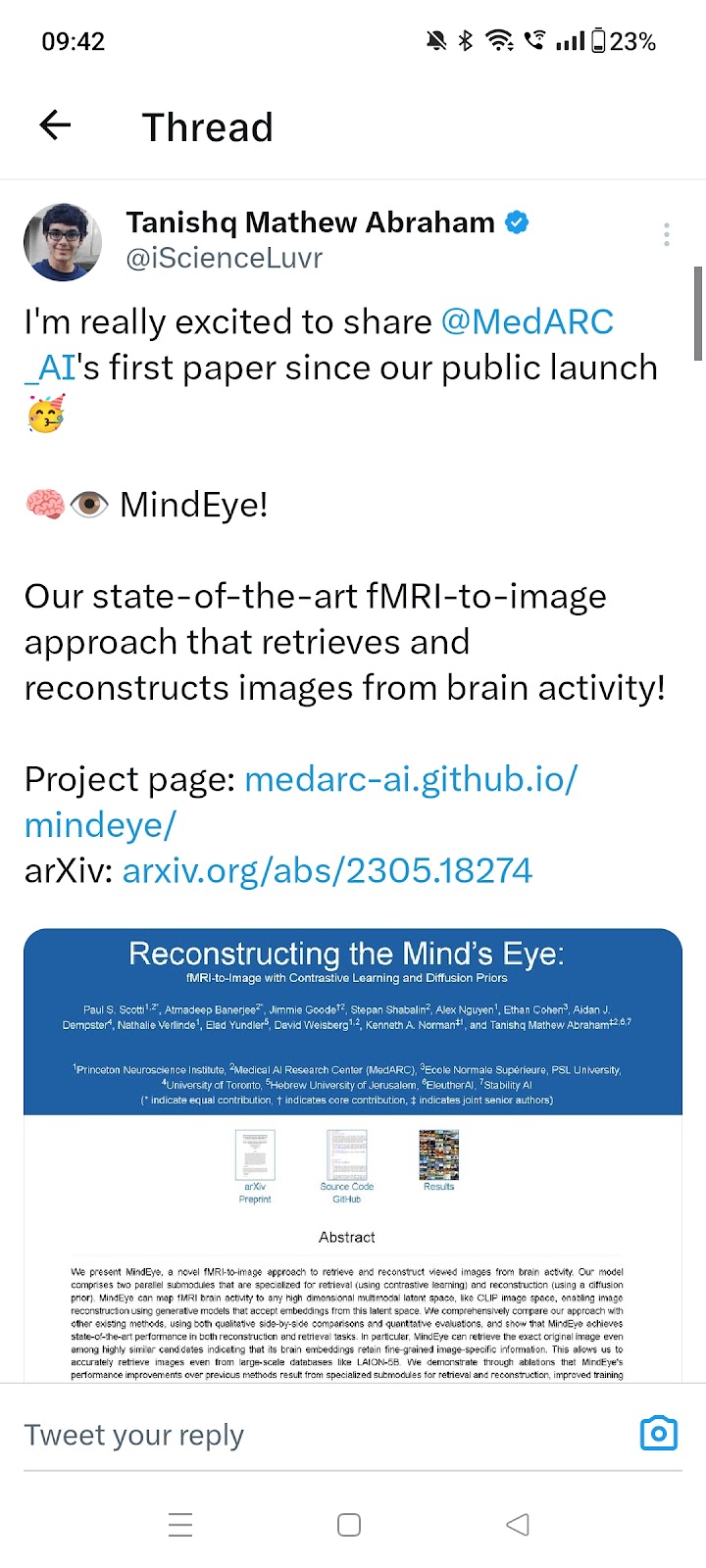
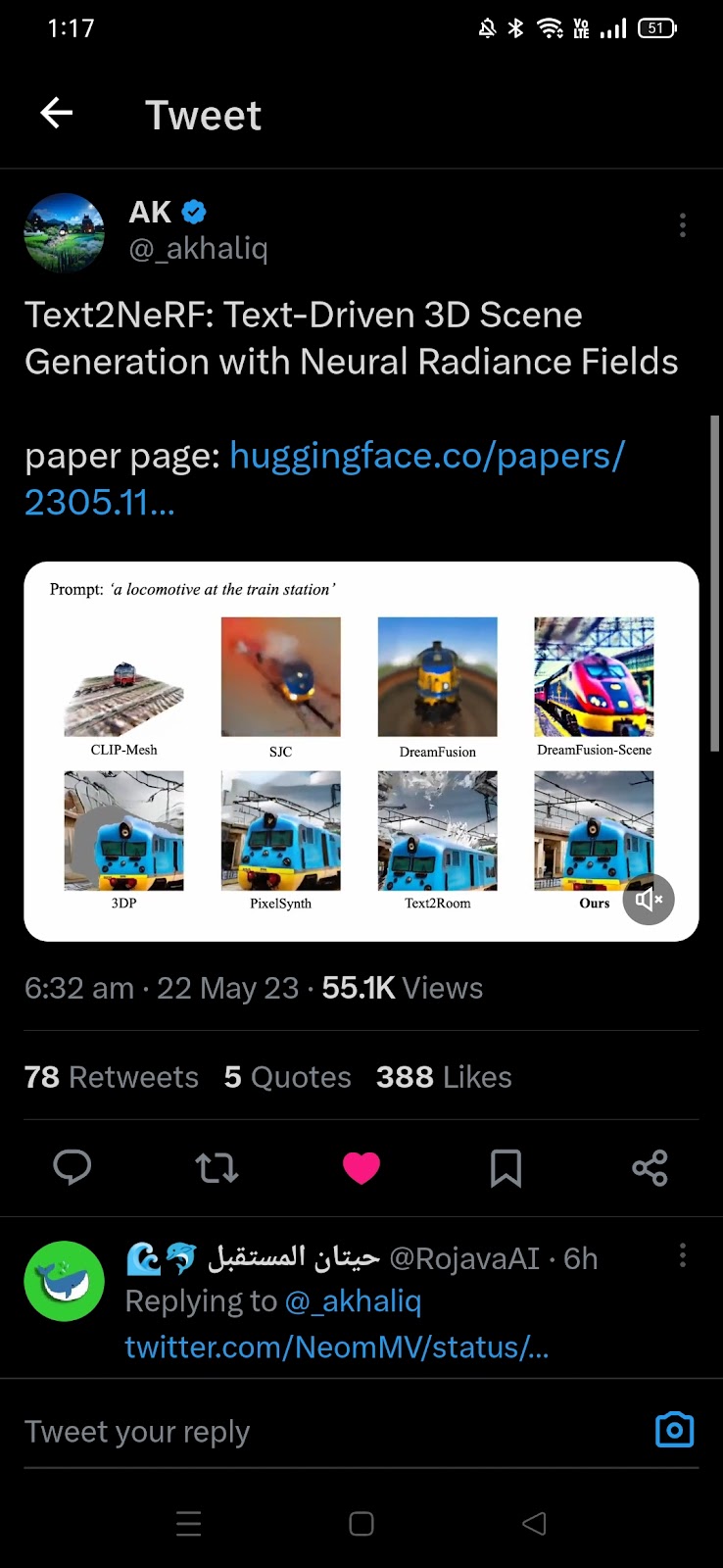
OpenAI: We trained an AI using process supervision — rewarding the thought process rather than the outcome — to achieve new state-of-art in mathematical reasoning #1145 Source Tweet
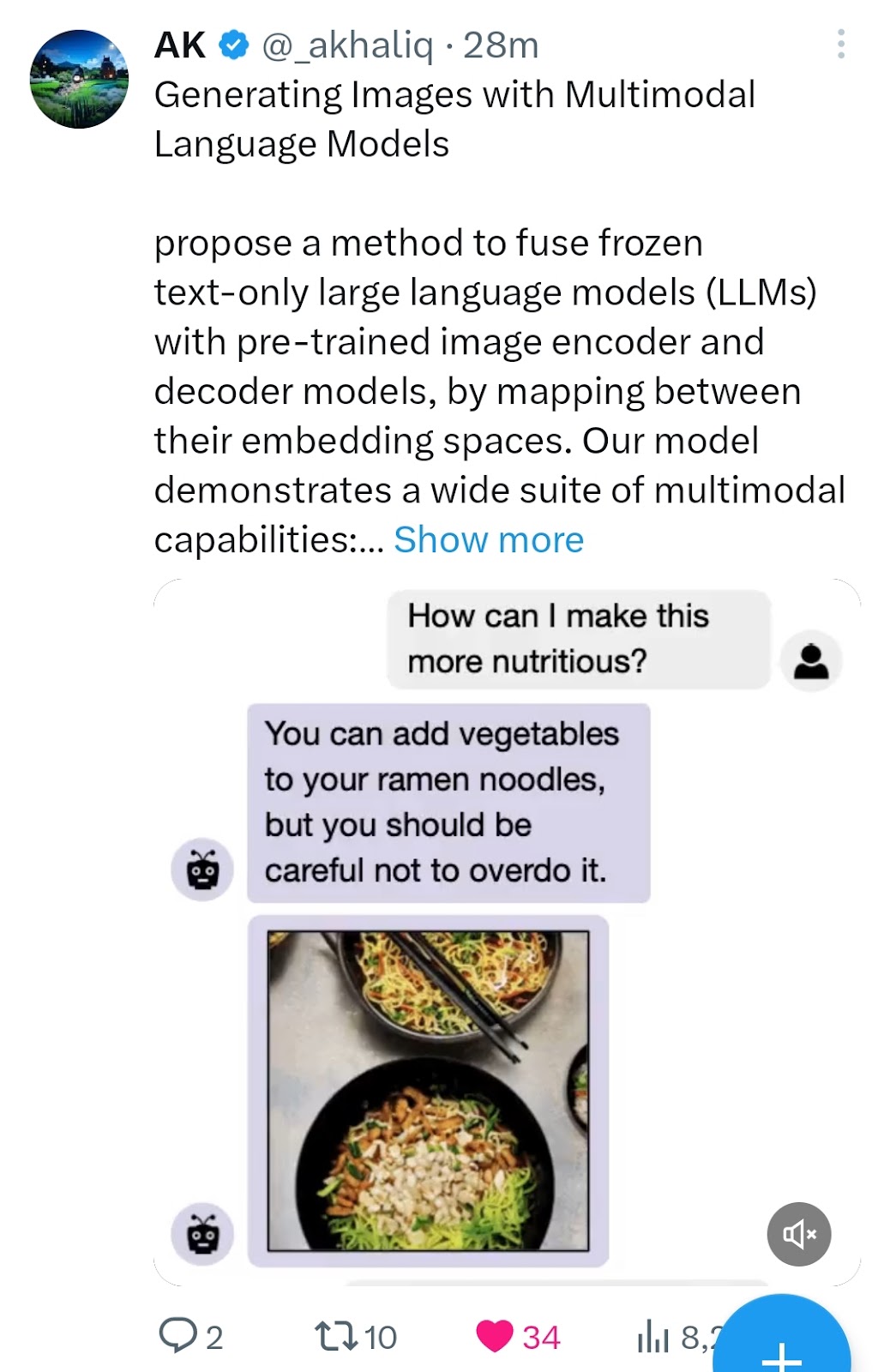
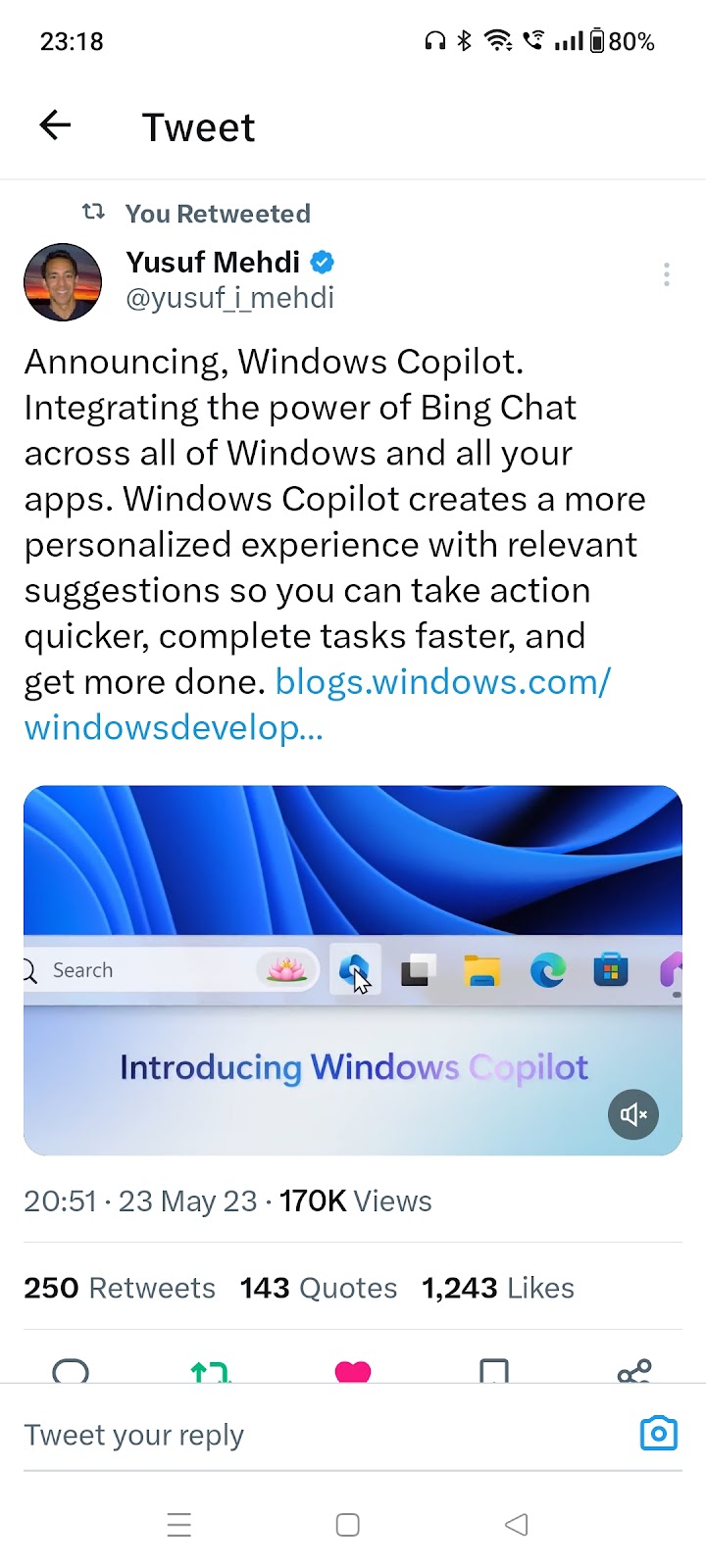
Any-to-Any Generation via Composable Diffusion - capable of generating any combination of output modalities, such as language, image, video, or audio, from any combination of input modalities #1115 Source
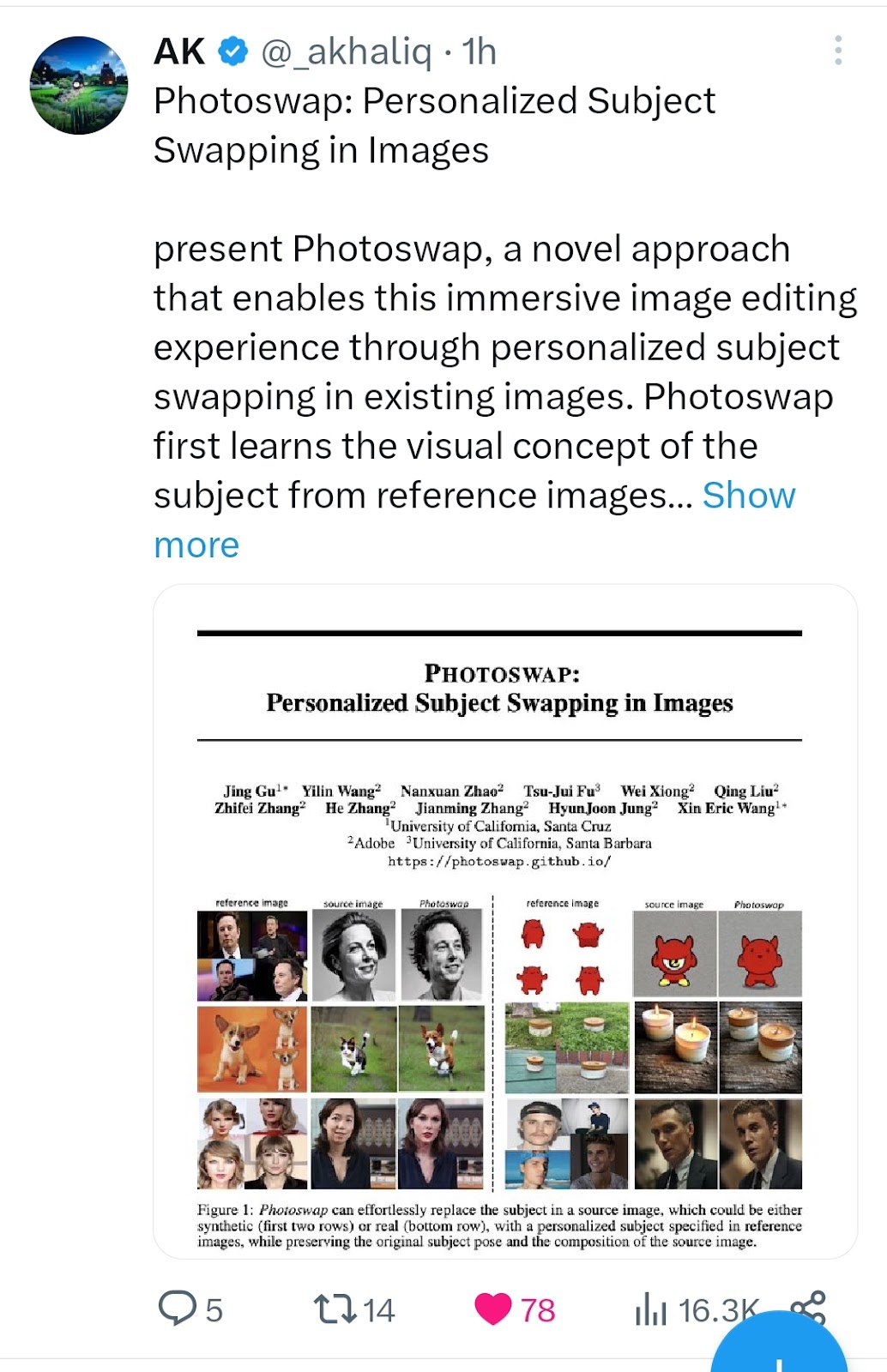
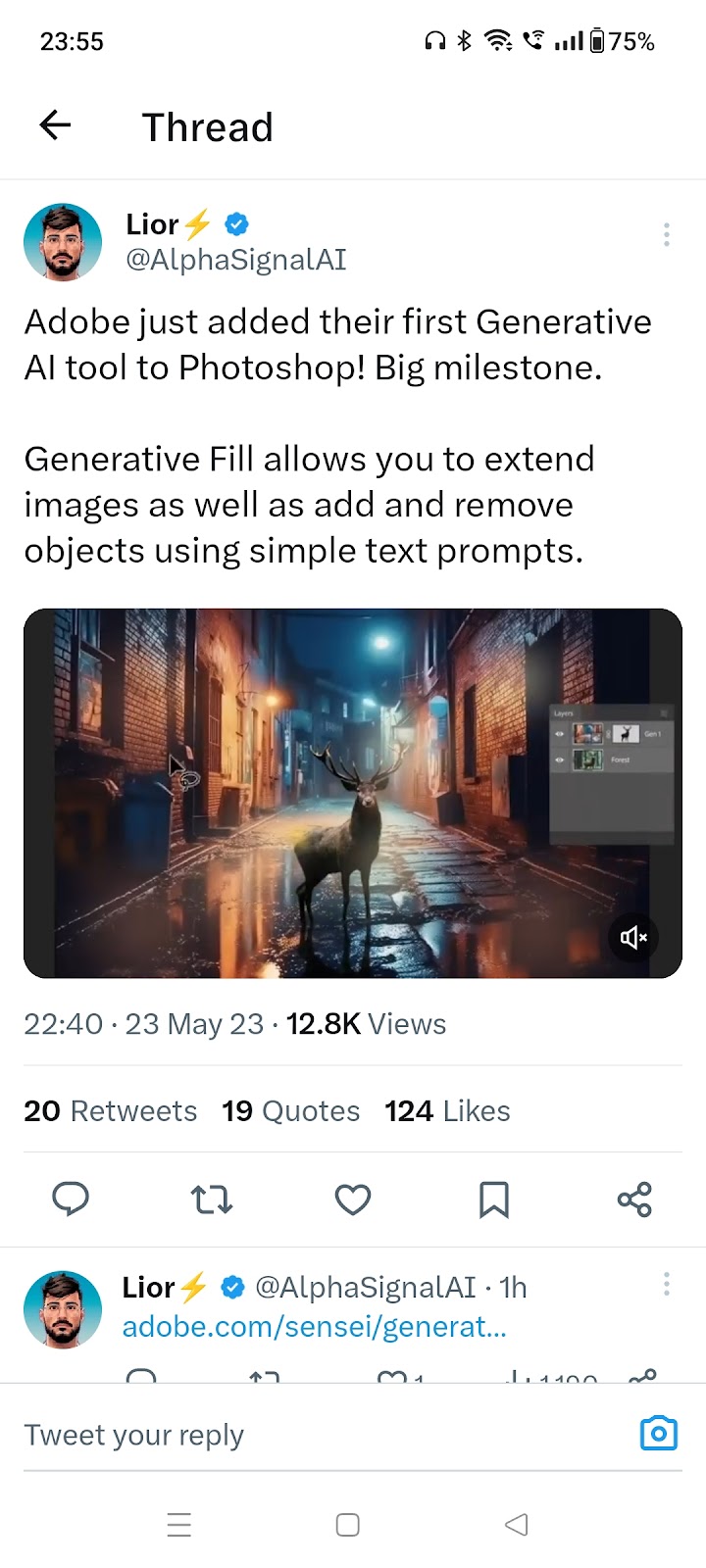
BlockadeLabs announced a Sketch mode for its Skybox AI image generator, which creates environments based on the lines you draw and your text prompt #1113 Source