FastChat-T5: our compact and commercial-friendly chatbot - Outperforms Dolly-V2 with 4x fewer parameters #1041 Get link Facebook X Pinterest Email Other Apps April 28, 2023 FastChat-T5: our compact and commercial-friendly chatbot - Outperforms Dolly-V2 with 4x fewer parameters #1041 Source Read more
Announcing StableVicuna, the AI World’s First Open Source RLHF LLM Chatbot #1040 Get link Facebook X Pinterest Email Other Apps April 28, 2023 Announcing StableVicuna, the AI World’s First Open Source RLHF LLM Chatbot #1040 Source Read more
Introducing DataComp, a new benchmark for multimodal datasets #1039 Get link Facebook X Pinterest Email Other Apps April 28, 2023 Introducing DataComp, a new benchmark for multimodal datasets #1039 Source Read more
Announcing the release of DeepFloyd IF text to image model - with research weights (open source) #1038 Get link Facebook X Pinterest Email Other Apps April 28, 2023 Announcing the release of DeepFloyd IF text to image model - with research weights #1038 Source Official Post Read more
SAD is able to perform 3D segmentation (segment out any 3D object) with RGBD inputs (or rendered depth images only) #1037 Get link Facebook X Pinterest Email Other Apps April 28, 2023 SAD is able to perform 3D segmentation (segment out any 3D object) with RGBD inputs (or rendered depth images only) #1037 Source Read more
Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model #1036 Get link Facebook X Pinterest Email Other Apps April 28, 2023 Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model #1036 Source Read more
ChatVideo: A Tracklet-centric Multimodal and Versatile Video Understanding System #1035 Get link Facebook X Pinterest Email Other Apps April 28, 2023 ChatVideo: A Tracklet-centric Multimodal and Versatile Video Understanding System #1035 Source Read more
Introducing Eleven Multilingual v1: Our New Speech Synthesis Model #1034 Get link Facebook X Pinterest Email Other Apps April 27, 2023 Introducing Eleven Multilingual v1: Our New Speech Synthesis Model #1034 Source Read more
Microsoft Designer expands preview with new AI design features #1033 Get link Facebook X Pinterest Email Other Apps April 27, 2023 Microsoft Designer expands preview with new AI design features #1033 Source Read more
Unleashing Infinite-Length Input Capacity for Large-scale Language Models with Self-Controlled Memory System #1032 Get link Facebook X Pinterest Email Other Apps April 26, 2023 Unleashing Infinite-Length Input Capacity for Large-scale Language Models with Self-Controlled Memory System #1032 Source Read more
Deepmind: Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning #1031 Get link Facebook X Pinterest Email Other Apps April 26, 2023 Deepmind: Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning #1031 Source Read more
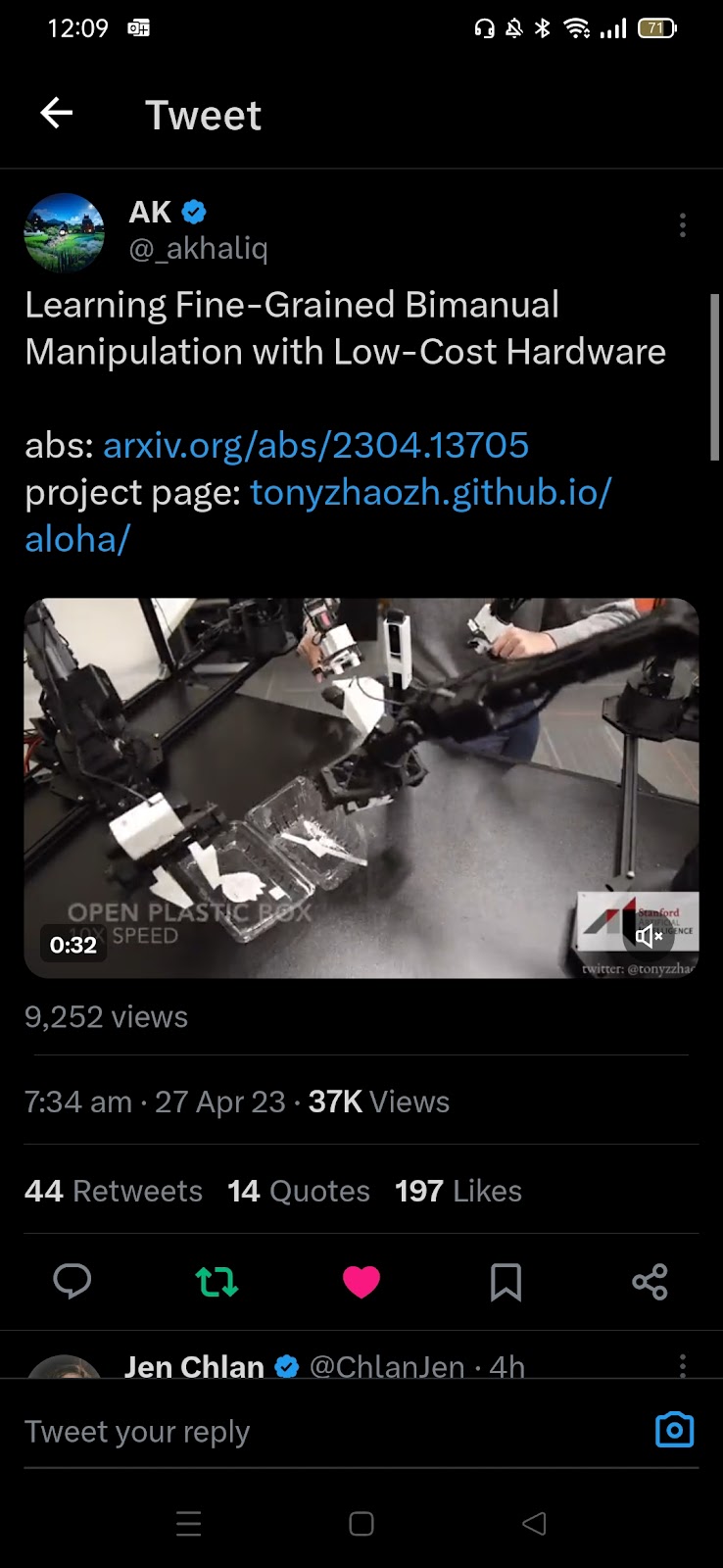
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware #1030 Get link Facebook X Pinterest Email Other Apps April 26, 2023 Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware #1030 Source Read more
TextDeformer: Geometry Manipulation using Text Guidance #1029 Get link Facebook X Pinterest Email Other Apps April 26, 2023 TextDeformer: Geometry Manipulation using Text Guidance #1029 Source Read more
Code for IF by deepfloydai is up - a text to image diffusion model (open source) #1028 Get link Facebook X Pinterest Email Other Apps April 26, 2023 Code for IF by deepfloydai is up - a text to image diffusion model (open source) #1028 Source Read more
Replit announces replit-code-v1-3b : a code language model that is 2.7B parameters and Open Source #1027 Get link Facebook X Pinterest Email Other Apps April 26, 2023 Replit announces replit-code-v1-3b : a code language model that is 2.7B parameters and Open Source #1027 Source Read more
TextMesh: Generation of Realistic 3D Meshes From Text Prompts #1026 Get link Facebook X Pinterest Email Other Apps April 26, 2023 TextMesh: Generation of Realistic 3D Meshes From Text Prompts #1026 Source Read more
Patch Diffusion: Faster and More Data-Efficient Training of Diffusion Models #1025 Get link Facebook X Pinterest Email Other Apps April 26, 2023 Patch Diffusion: Faster and More Data-Efficient Training of Diffusion Models #1025 Source Read more
AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head #1024 Get link Facebook X Pinterest Email Other Apps April 26, 2023 AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head #1024 Source Read more
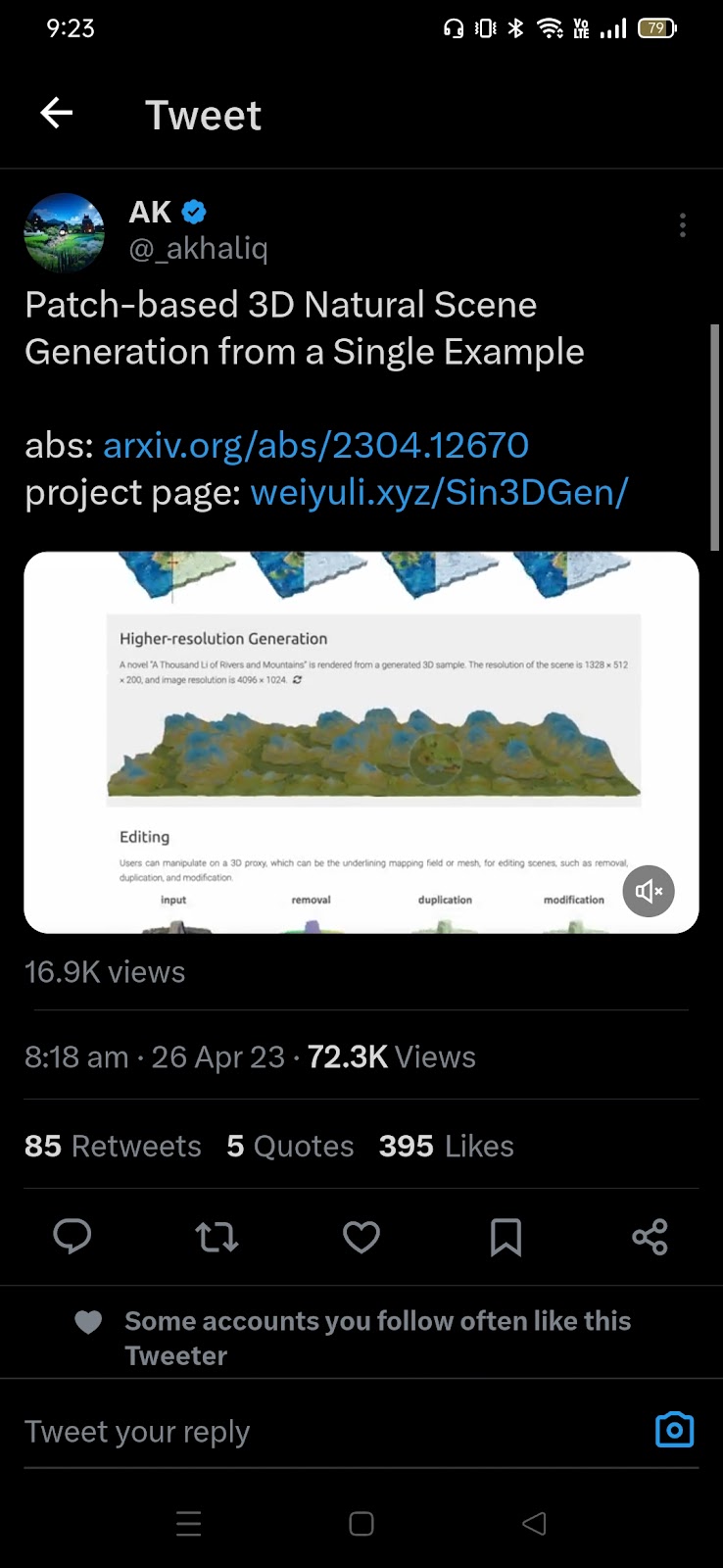
Patch-based 3D Natural Scene Generation from a Single Example #1023 Get link Facebook X Pinterest Email Other Apps April 26, 2023 Patch-based 3D Natural Scene Generation from a Single Example #1023 Source Read more
Towards Realistic Generative 3D Face Models #1022 Get link Facebook X Pinterest Email Other Apps April 26, 2023 Towards Realistic Generative 3D Face Models #1022 Source Read more
Stability AI's Image Upscaling API - upscale any image without losing any sharpness #1021 Get link Facebook X Pinterest Email Other Apps April 26, 2023 Stability AI's Image Upscaling API - upscale any image without losing any sharpness #1021 Source Read more
Bill Gates says A.I. chatbots will teach kids to read within 18 months: "You’ll be ‘stunned by how it helps.’ #1020 Get link Facebook X Pinterest Email Other Apps April 25, 2023 Bill Gates says A.I. chatbots will teach kids to read within 18 months: "You’ll be ‘stunned by how it helps.’ #1020 Source Read more
HuggingChat: open source alternative to ChatGPT #1019 Get link Facebook X Pinterest Email Other Apps April 25, 2023 HuggingChat: open source alternative to ChatGPT #1019 Source Read more
‘Avengers’ Director Joe Russo Predicts AI Could Be Making Movies in ‘Two Years’: It Will ‘Engineer and Change Storytelling’ #1018 Get link Facebook X Pinterest Email Other Apps April 25, 2023 ‘Avengers’ Director Joe Russo Predicts AI Could Be Making Movies in ‘Two Years’: It Will ‘Engineer and Change Storytelling’ #1018 Source My Reddit Post Read more
Speed Is All You Need: Optimizing Stable Diffusion For Mobile Devices (under 12 seconds) #1017 Get link Facebook X Pinterest Email Other Apps April 25, 2023 Speed Is All You Need: Optimizing Stable Diffusion For Mobile Devices (under 12 seconds) #1017 Source Read more
AutoNeRF: Training Implicit Scene Representations with Autonomous Agents #1016 Get link Facebook X Pinterest Email Other Apps April 25, 2023 AutoNeRF: Training Implicit Scene Representations with Autonomous Agents #1016 Source Read more
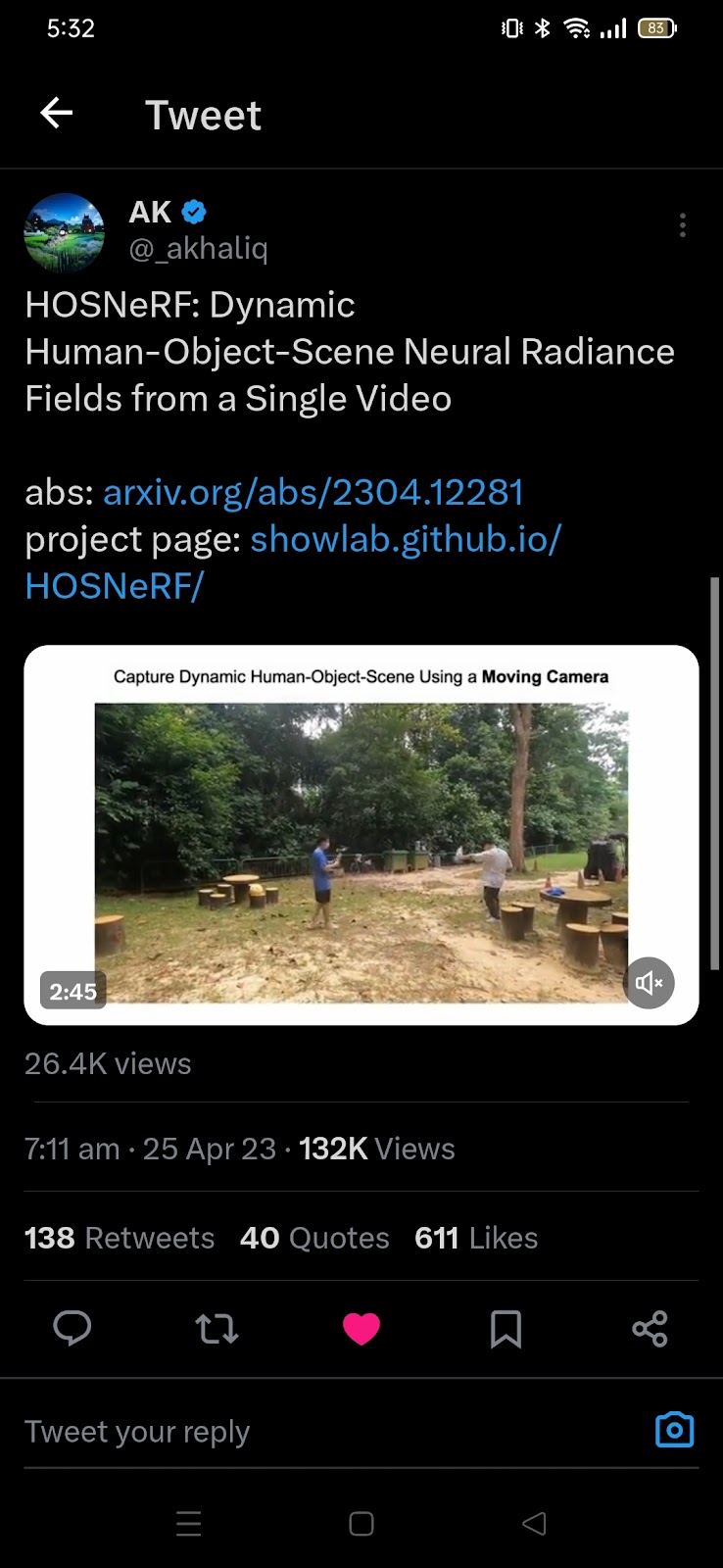
HOSNeRF: Dynamic Human-Object-Scene Neural Radiance Fields from a Single Video #1015 Get link Facebook X Pinterest Email Other Apps April 25, 2023 HOSNeRF: Dynamic Human-Object-Scene Neural Radiance Fields from a Single Video #1015 Source Read more
Segment Anything in 3D with NeRFs #1014 Get link Facebook X Pinterest Email Other Apps April 25, 2023 Segment Anything in 3D with NeRFs #1014 Source Read more
Track Anything: Segment Anything Meets Videos #1013 Get link Facebook X Pinterest Email Other Apps April 25, 2023 Track Anything: Segment Anything Meets Videos #1013 Source Read more
This AI Can Design Complex Proteins Perfectly Tailored to Our Needs #1012 Get link Facebook X Pinterest Email Other Apps April 24, 2023 This AI Can Design Complex Proteins Perfectly Tailored to Our Needs #1012 Source Read more
Introducing Chatbot Arena - Which LLM is better? #1011 Get link Facebook X Pinterest Email Other Apps April 24, 2023 Introducing Chatbot Arena - Which LLM is better? #1011 Source Read more
Some AI videos generated using Gen-2 by runwayml #1010 Get link Facebook X Pinterest Email Other Apps April 23, 2023 Some AI videos generated using Gen-2 by runwayml #1010 Vid1 Vid2 Vid3 Vid4 Vid5 Vid6 Vid7 Vid8 Vid9 Vid10 Read more
Scaling Transformer to 2 Million tokens and beyond with RMT #1009 Get link Facebook X Pinterest Email Other Apps April 23, 2023 Scaling Transformer to 2 Million tokens and beyond with RMT #1009 Source Read more
Grimes allowing people to use her voice on AI generated songs without getting copyright #1008 Get link Facebook X Pinterest Email Other Apps April 23, 2023 Grimes allowing people to use her voice on AI generated songs without getting copyright #1008 Source Read more
Ask-Anything, tool for chatting about video with chatGPT, miniGPT4 and StableLM #1007 Get link Facebook X Pinterest Email Other Apps April 23, 2023 Ask-Anything, tool for chatting about video with chatGPT, miniGPT4 and StableLM #1007 Source Read more
3DCoMPaT++: a richly annotated, multimodal 2D/3D dataset of more than 10 million stylized 3D shapes #1006 Get link Facebook X Pinterest Email Other Apps April 22, 2023 3DCoMPaT++: a richly annotated, multimodal 2D/3D dataset of more than 10 million stylized 3D shapes #1006 Source Read more
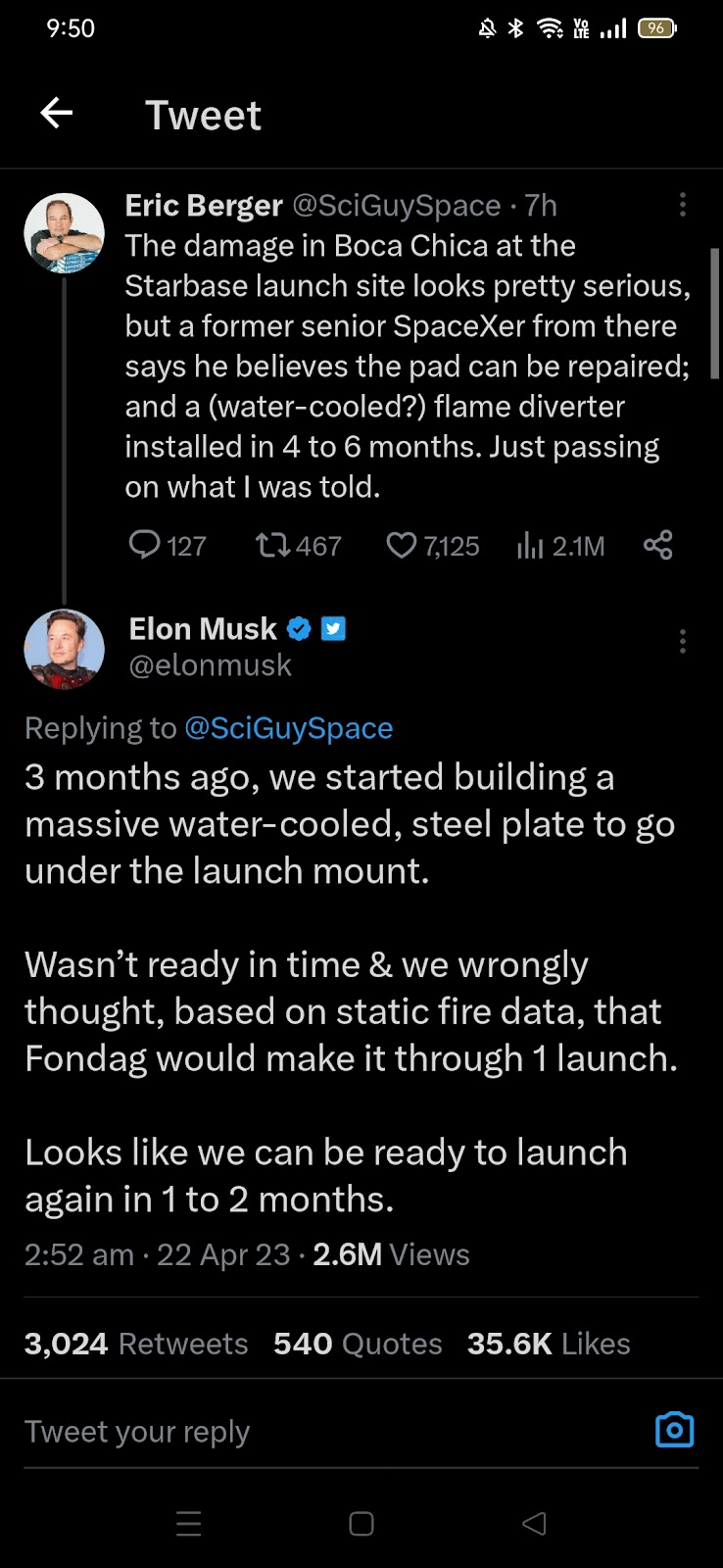
SpaceX's Starship could have 2nd launch test within the next 2 months #1005 Get link Facebook X Pinterest Email Other Apps April 21, 2023 SpaceX's Starship could have 2nd launch test within the next 2 months #1005 Source Read more
Google's Bard adds coding & debug abilities in 20+ languages #1004 Get link Facebook X Pinterest Email Other Apps April 21, 2023 Google's Bard adds coding & debug abilities in 20+ languages #1004 Source Read more
DeepMind and the Brain team from Google Research will become a new unit: Google DeepMind #1003 Get link Facebook X Pinterest Email Other Apps April 20, 2023 DeepMind and the Brain team from Google Research will become a new unit: Google DeepMind #1003 Source Read more
NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion Models #1002 Get link Facebook X Pinterest Email Other Apps April 20, 2023 NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion Models #1002 Source Read more
Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models #1001 Get link Facebook X Pinterest Email Other Apps April 20, 2023 Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models #1001 Source Read more
Pretrained Language Models as Visual Planners for Human Assistance #1000 Get link Facebook X Pinterest Email Other Apps April 20, 2023 Pretrained Language Models as Visual Planners for Human Assistance #1000 Source Read more
Reference-guided Controllable Inpainting of Neural Radiance Fields #999 Get link Facebook X Pinterest Email Other Apps April 20, 2023 Reference-guided Controllable Inpainting of Neural Radiance Fields #999 Source Read more
Reference-based Image Composition with Sketch via Structure-aware Diffusion Model #998 Get link Facebook X Pinterest Email Other Apps April 20, 2023 Reference-based Image Composition with Sketch via Structure-aware Diffusion Model #998 Source Read more
AMT: All-Pairs Multi-Field Transforms for Efficient Frame Interpolation #997 Get link Facebook X Pinterest Email Other Apps April 20, 2023 AMT: All-Pairs Multi-Field Transforms for Efficient Frame Interpolation #997 Source Read more
h2oGPT is out. A new 20 billion parameter instruction-following large language model licensed for commercial use #996 Get link Facebook X Pinterest Email Other Apps April 20, 2023 h2oGPT is out. A new 20 billion parameter instruction-following large language model licensed for commercial use #996 Source Read more
Bark - an Open Source Audio Generation Model #995 Get link Facebook X Pinterest Email Other Apps April 20, 2023 Bark - an Open Source Audio Generation Model #995 Source Examples Read more
Whisper JAX ⚡️ is a highly optimised Whisper implementation for both GPU and TPU (70x faster than Whisper) #994 Get link Facebook X Pinterest Email Other Apps April 20, 2023 Whisper JAX ⚡️ is a highly optimised Whisper implementation for both GPU and TPU (70x faster than Whisper) #994 Source Read more
SpaceX Starship's First Orbital Flight Test #993 Get link Facebook X Pinterest Email Other Apps April 20, 2023 SpaceX Starship's First Orbital Flight Test #993 Source Read more